A practical guide on reducing a Rust's binary runtime RAM usage
I am proud to announce awww can now idle at just around 230 Kb in my machine using the no-libc-daemon branch (note: we need some magical incantions to make the code compile in that branch, so compile the daemon using the build-daemon.sh script, and then compile the client separately with cargo build --package awww --release):
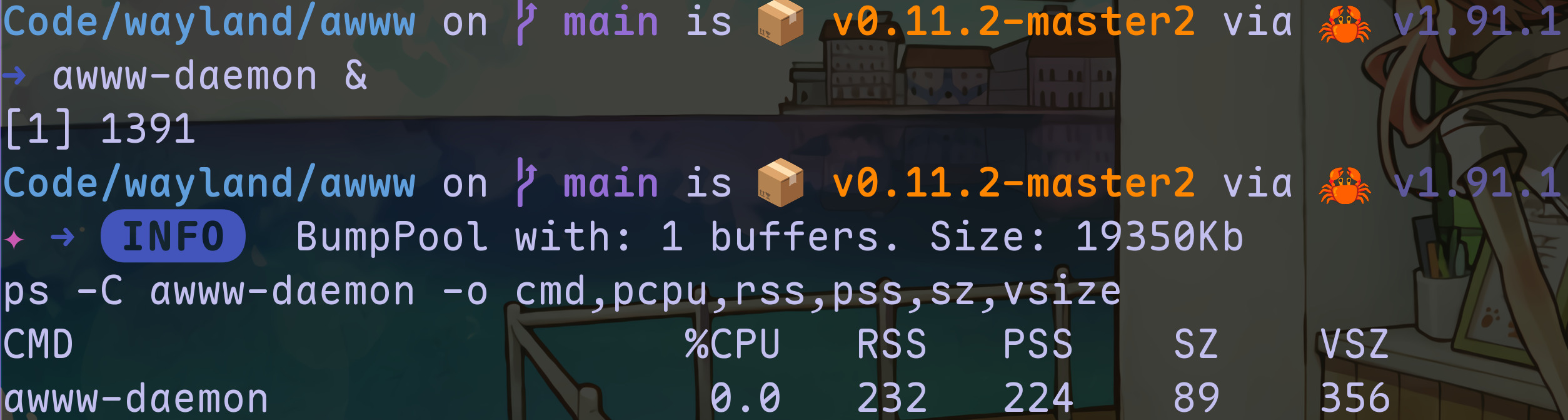
But wait! What's that 19350Kb buffer we are allocating? That's the buffer we memory map to load the initial image, which we promptly unmap after we are done setting the wallpaper, and thus its cost disappears.
The no-libc-daemon branch implementation unfortunately currently only works on Linux machines. If you are on another Unix, you can still use the main branch, which will idle at around 2.3 Mb (about 10x as much, but still much lower than pretty much every other wallpaper setter for wayland I know of).
I have always been fascinated by projects like min-sized-rust, trying to create small Rust executables, or the famous post A Whirlwind Tutorial on Creating Really Teensy ELF Executables for Linux , which walks us through the creation of a 45 byte executable Linux binary. However, these posts often have small practical applicability, since people will usually not go through the trouble of using any of their techniques, because they would be too taxing, impractical, or error-prone. For example, one of min-sized-rust's recommendations is to avoid all formatting, as Rust's core::fmt includes a lot of code in the final binary. While this is certainly true, how many of us are willing to let go of runtime formatting? It would imply, at least, using static strings for all debugging, logging, error reporting and user interfaces. Essentially impossible for many projects.
In this post, I will go over every single technique/strategy I've employed in order to achieve awww's small memory footprint. Note this is runtime memory use, not simply binary size. That does become a factor once we get small enough though (since the code needs to be loaded in memory for it to be executed), and so there is some stuff whose primary purpose is reducing code size. These are all practical techniques that you can actually use without greatly sacrificing functionality. They include several alternatives to things you find in Rust's std. Note, however, that you will have to implement more things than usual by hand, though none of them should be super complicated.
We will begin with something that's very specific to awww, and then branch into ideas that can be applied much more generally. They are presented in no particular order, and some of them are independent from each other.
As a final note, keep mind that while all that follows has been measured and verified by me, you should always measure things yourself in your own projects to ensure your are getting the desired results. You can use cargo-bloat to see what's taking up space in your binary, and the ps command while the program is running to see what's its resident set size. Tools like valgrind and heaptrack can be very helpful, but after we overload the default system allocator, they may no longer report reliable results, so treat them with some care.
Table of Contents
awwwspecific- Get rid of
stdusingrustix - Get rid of
libcusingrustixandorigin - Limit allocations
- Get rid of generics (as much as it is reasonable)
- Reduce
structsizes - Manual
logimplementation - Manual
CStrparsing
1. awww specific
As mentioned, we begin with the most important things for awww that are specific to it, and probably not relevant for other applications.
1.1. waybackend: custom wayland client implementation
waybackend is my own implementation of the wayland protocol, client side. It was designed to be much more memory efficient than the alternatives, the smithay client toolkit and wayrs.
It emphasizes low-level operations. We forego most of the things usual wayland implementations use to make their libraries more ergonomic. Most importantly, the wayland protocol request calls themselves are not type-checked, so you can do something nonsensical like ask for a keyboard handle from a pointer. This means you need to write the code while constantly consulting the wayland protocol documentation. Although, in my experience, once you get used to it, it's not that bad, since the requests are all nicely divided into modules.
Both smithay and wayrs seem to expose an API heavily inspired by the canonical C libwayland implementation. waybackend abandoned that altogether, and instead tries to implement everything directly with as little overhead as possible. One of the biggest wins is how we store wayland objects: as single user-defined enum that will most of the time be a single byte. In contrast, wayrs uses 16: a pointer to a static struct and two full u32s. I won't delve further into waybackend's design here; you can look at the code to know more about it, and awww is a nice example of what using it looks like.
If you do plan on using waybackend, keep in mind it is significantly less battle-tested than the alternatives, and a bit of a pain in the ass. In general, the lesson here is that you should not be afraid to roll your own code when the existing libraries are holding you back.
1.2. Do not store the image's bytes
If you have to set a wallpaper, naturally you have to store the image's pixel byte information... right? Well, not really. The way the wayland protocol works, we have to send back to the compositor a shared memory file as a buffer containing the relevant data. Once we do, we can simply unmap it and it will disappear from our program's address space.
What if we need to redraw it? This is why other programs usually keep the original image's data in memory. They can resize it dynamically as the output resolution or scale change, without having to reparse the image file. Instead, we just keep the image's path, and if a resize happens, we call the awww client to send in a new image with the correct dimensions. The disadvantage is, of course, that if the user deletes or moves the image after setting it, our daemon won't be able to resize it (I believe this is probably why most applications just load it once, so they do not have to worry about this edge case).
But wait, where the hell are the bytes then?
So we are not storing the image's bytes anywhere. But if we drag a window across the desktop, our compositor will draw the background wherever the window does not cover. This means clearly someone knows what the images bytes are supposed to be. Who this is will depend on your compositor's implementation.
If your compositor unmaps the shared memory file after reading it once (like we do), and does not store its bytes in its own private address space, then all is well. The compositor can do that by, for example, storing the data directly in GPU buffers. If it doesn't unmap the memory, or if it keeps a copy of the data in its private address space, then our memory efficiency would be an illusion, because the memory is still being used, just not by us. I believe most compositors with a GPU renderer do not keep neither a private copy nor the memory mapped bytes, and so overall this leads to a very nice win.
2. Get rid of std using rustix
Now we begin with the more general methods. The Rust std may be highly optimized, but it still needs to support Windows, MacOS and Unix, even though in many cases we care only about one of those targets. Furthermore, a lot of extra stuff the standard library does under the hood may be simply unnecessary for us, or we may have a specific use case that can be implemented more efficiently. Another issue is that it comes pre-compiled, causing it to miss possible optimizations for our binary. To see the full extent of these difference, see the comparison in section 3 (tldr: even when static linking against musl with fat link time optimizations, the version without std runs while consuming almost 10x less memory).
The rustix library will be our go-to option for a nice, thin wrapper over the OS's syscalls. Even if you can't go full no-std, I would still recommend using it as little as possible and writing as much as you can with rustix. That is the path awww has currently taken, since no-std would require Rust nightly to compile for now, and I do not want to impose that on my users. Using rustix is a lot like using C: low-level syscalls and a lot of manpage reading to make sure you aren't doing something stupid. Unlike C, rustix will force us to properly treat all the errors that could come from a syscall, and so it should be much safer. I won't lie: if you are used to Rust, there will be an initial learning curve. But to me learning how to do things with rustix has been very interesting and liberating: peeling off an extra layer of abstraction. It will also improve your abilities with other low-level systems language, since you will be more aware of what syscalls are underpinning all their abstractions. To make it a little bit easier for yourself, you can do it gradually, rewriting your program piece by piece to use rustix instead of std in more and more places.
One of the most important aspects of rustix is how it does not depend on libc for Linux targets. Instead, it implements the syscalls directly in inline assembly, allowing certain functions to be inlined all the way down (std will eventually make a libc call for its implementations). This unlocks the main optimization we discuss in section 3: getting rid of libc itself.
After you get used to it, using rustix is not that bad, but there are a few pain points and gotchas that may be more annoying than others. I will talk about some of them.
2.1. std::path alternatives
This is the most important and most annoying module to replace from std. It is important because it has direct influence on how efficient the syscalls will be made. Specifically, rustix has an Arg trait that's more or less equivalent to std's AsRef<Path>. The issue is that, even though it has several blanket implementations, it will only reliably not allocate any data when used as a CStr or CString. This means calling rustix functions that use an Arg (for example, rustix::fs::open to open a file descriptor) will almost certainly perform an extra allocation and memcpy if you pass to it a Vec<u8>, &[u8], String or &str (it would only not allocate if they end with a null byte, because that's usually the syscalls' requirement).
So, the solution is simple: use a no-std Path/PathBuf implementation backed by a CString, so that whenever we have to pass it to a rustix call, it is already in the correct format. Yeah, I couldn't find any crates that do that. There are many alternative Path implementations, but they all seem to use Vec<u8>, and do not append an extra null byte at the end of their addresses. In the end, I resorted to my own custom implementation, that implements just what I need, but I would appreciate someone publishing a well-tested crate I could use instead.
To be clear, this is also not a highly theoretical, impractical win. The extra allocation and memcpy was genuinely, measurably increasing the binary size, because every syscall had this huge amount of (possibly panicking, since allocation is fallible!) extra inlined code because the type we were passing as Arg did not guarantee it terminated with a null byte.
(Note: it gets inlined because we are optimizing for speed rather than size. We have to do this because otherwise Rust won't vectorize some of our transition effects, making them too slow to give smooth results. If you were optimizing for size instead, the difference would probably be much smaller, and the only real problem would be the extra allocation.)
2.2. std::env alternatives
To access argc and argv in no-std code, since you do not have std::env, you will also need to use no-main, and your main function will look like this:
#[unsafe(no_mangle)]
pub extern "C" fn main(
argc: core::ffi::c_long,
argv: *const *const core::ffi::c_char,
) -> core::ffi::c_long {
// ...
0
}
Welcome to C-style argv parsing, motherfucker! It's not that bad; the main pain point is that you can't do something like:
match cstr {
// This does not compile
c"-h" | c"--help" => {
//print help
},
c"-v" | c"--version" => {
//print version
}
}
But this can be easily solved by calling to_bytes:
match cstr.to_bytes() {
b"-h" | b"--help" => {
//print help
},
b"-v" | b"--version" => {
//print version
}
}
If you want to support getopt-like parsing, things get really annoying. I do not know of any CLI parsing crate that works with no-std, though, to be fair, I didn't look very hard. If someone does know of one, send me an email and I will link it here!
What about accessing environment variables?
Basically, either just use libc's getenv, or, if you want a Rust-only solution, this code:
/// # Safety
///
/// The `env` parameter must **NOT** end with an `=` byte
/// (before the final null byte, of course).
pub unsafe fn getenv(env: &core::ffi::CStr) -> Option<&core::ffi::CStr> {
unsafe extern "C" {
static environ: *const *const core::ffi::c_char;
}
let mut ptr = environ;
loop {
let cptr = unsafe { ptr.read() };
if cptr.is_null() {
return None;
}
// SAFETY: environ is composed of null terminated strings,
// so this should be safe
let cstr = unsafe { core::ffi::CStr::from_ptr(cptr) };
let cstr_bytes = cstr.to_bytes_with_nul();
if let Some(value) = cstr_bytes.strip_prefix(env.to_bytes()) {
// SAFETY:
// Because `env` does not end with a `=` byte, value[1..] will
// always skip the `=` byte, and the rest of the string is
// guaranteed to end in a null byte, since it was created by
// removing the prefix of another CStr, which also ends in a
// null byte
let value = unsafe {
core::ffi::CStr::from_bytes_with_nul_unchecked(&value[1..])
};
return Some(value);
}
ptr = unsafe { ptr.add(1) };
}
}
It should be easy to adapt it to a fully safe function. You just have to decide what to do if the env parameter ends with a '=' byte: panic? Return None straight away? Something else entirely?
The above code works because the environ pointer (which should always be defined as long as you are linking libc) is a null-terminated array of pointers. If you need to modify it instead, things get hairy. I would advise just using libc in this case.
2.3. std::sync::Once alternatives
If you need std::sync::Once to do safe global state initialization, you will need to use an alternative implementation. You can try once_cell or using the following template:
fn get_or_init() -> YourType {
use core::cell::UnsafeCell;
use core::sync::atomic;
// if your type can be represented by Atomics, you can implement
// all of this using just safe code!
static INIT: UnsafeCell<YourType> = UnsafeCell::new(YourType::new());
static DONE: atomic::AtomicBool = atomic::AtomicBool::new(false);
static FLAG: atomic::AtomicBool = atomic::AtomicBool::new(false);
if !FLAG.swap(true, atomic::Ordering::SeqCst) {
let ptr = INIT.get();
unsafe {
ptr.write(
// your initialization code goes here
// **IMPORTANT**: you could deadlock if you call this
// function in a signal handler: if this code did not
// finish running, FLAG is set, but not DONE, and so
// the code will stay in the busy loop below forever.
// These types of problems are usually referred to as
// "reentrancy"
)
};
DONE.store(true, atomic::Ordering::SeqCst);
}
while !DONE.load(atomic::Ordering::SeqCst) {
// Busy wait. For this to be efficient, make sure the above
// initialization is fast.
// Alternatively, you can delete this altogether if you
// know only a single thread will call this function
// during initialization. In this case, make sure the
// initial value of 'INIT' is something sensible.
// We would no longer deadlock in a signal handler, but we
// can still potentially try to read 'INIT' before the
// initialization has finished, so make sure it isn't in a
// fundamentally invalid state.
}
unsafe { INIT.get().read() }
}
2.4. How do I spawn threads/processes?
The same you'd do it in good old C: pthread_create for threads; fork and exec for processes. Make sure to read the documentation carefully so you don't do any oopsies. Many things here are surprisingly easy to get wrong, so also make sure to test it thoroughly.
You can use libc's implementation, or, if you are feeling adventurous, for fork and exec you can try rustix's experimental implementations. These are hidden behind a #[doc(hidden)] module and runtime crate feature, and are not guaranteed to be stable, but they do get the job done without involving libc in Linux targets. As far as threads go, I believe libc is your only option.
2.5. Well formatted panics without std
Somewhat annoyingly, pretty much every example I've seen in the internet that implements their own panic handler doesn't do anything interesting with it; they just exit immediately. Here's what a proper panic handler that prints useful information and doesn't fuck up your tests looks like:
#[cold]
#[inline(never)]
#[panic_handler]
#[cfg(not(test))]
fn panic_handler(info: &core::panic::PanicInfo) -> ! {
if let Some(loc) = info.location() {
log::fatal!(
"PANIC AT {}:{}:{}: {}",
loc.file(),
loc.line(),
loc.column(),
info.message()
);
} else {
log::fatal!("PANIC: {}", info.message());
}
libc::abort();
}
Wait, what's log::fatal!? fatal! does not exist in the standard log crate. Yeah, I implemented my own logging, for reasons that are explained later. Overall, this isn't that important; whatever you decide to print with, make sure you use the location information if it is available and DO NOT ALLOCATE MEMORY IF YOU DO NOT HAVE TO (VERY IMPORTANT). This will be called if memory allocation fails, and so if your printing implementation naively allocates memory every time, you are going to get some very fun errors. You can avoid allocations when printing core::fmt::Arguments by doing this:
let msg = match arguments.as_str() {
Some(s) => ::alloc::borrow::Cow::Borrowed(s),
None => ::alloc::borrow::Cow::Owned(msg.to_string()),
};
// now you just get the bytes through msg.as_bytes()
3. Get rid of libc using origin
Let's talk about C for a bit. Specifically, let's talk about its standard library. You see (hehe), C's standard library includes a bunch nonsense we do not need. To show this, let us compile and run three versions of the same application. This is its C code:
#include <time.h>
int main(void) {
struct timespec tm = {10, 0};
nanosleep(&tm, NULL);
return 0;
}
And this is the same code in nasm x86_64 assembly:
%define SYS_NANOSLEEP 35
%define SYS_EXIT 60
global _start
section .rodata
timespec: dq 10,0
section .text
_start:
mov rax, SYS_NANOSLEEP
mov rdi, timespec
xor rsi, rsi
syscall
mov rax, SYS_EXIT
xor rdi, rdi
syscall
Now, remember, as I mentioned at the very top of this post, we care about runtime memory usage, not binary size. We will be measuring that with the ps command, using RSS, PSS, SZ and VSZ. These all measure memory usage in some way, but they differ in the specifics. Check out ps's man page for more information. The most important one that most people pay attention to is usually RSS.
To compile these programs, use the following commands:
# compile the C program, dynamically linked in a system with GLIBC
gcc sleep.c -Oz -flto -o sleep
# compile the C program statically using MUSL. I am in a GLIBC
# Linux distro, so we gotta do something like:
gcc sleep.c /usr/lib/musl/lib/libc.a -static -Oz -flto -o sleep_static
# nasm needs two commands for full compilation
nasm -felf64 sleep.nasm -o sleep_nasm.o
ld -static -o sleep_nasm sleep_nasm.o
Now, let's run all three of them and collect their ps metrics:
$ ./sleep & ./sleep_static & ./sleep_nasm &
[1] 7816
[2] 7817
[3] 7818
$ ps -C sleep,sleep_static,sleep_nasm -o cmd,rss,pss,sz,vsize
CMD RSS PSS SZ VSZ
./sleep 1516 122 653 2612
./sleep_static 24 24 46 184
./sleep_nasm 20 20 45 180
As you can see, when we dynamic link against glibc we include a bunch of stuff we do not need, which end up being loaded at runtime and increase our memory usage. On the other hand, compiling with static linking with musl and using link time optimizations leads to code almost equivalently efficient to the manual assembly version. Note that musl itself is much more lightweight than glibc, which is another important contributing factor. But the annoying thing is that we can't really tell our users to always use static linking against musl, unless we deploy an already-compiled static binary. This is very much a possibility, but from my understanding that is not going to fly with most distributions.
Let's try comparing the Rust equivalent of this program. We'll have 4 versions: std+glib,no-std+glib, std+musl and no-std+musl. Note Rust will statically link the musl versions by default. Here is the code with std:
pub fn main() {
let tm = libc::timespec {
tv_sec: 10,
tv_nsec: 0,
};
unsafe { libc::nanosleep(&tm, core::ptr::null_mut()) };
}
And here's the code without std:
#![no_std]
#![no_main]
#[link(name = "c")]
unsafe extern "C" {}
#[unsafe(no_mangle)]
pub fn main(_argc: isize, _argv: *const *const char) -> isize {
let tm = libc::timespec {
tv_sec: 10,
tv_nsec: 0,
};
unsafe { libc::nanosleep(&tm, core::ptr::null_mut()) };
0
}
#[panic_handler]
pub fn panic_handler(_: &core::panic::PanicInfo) -> ! {
unsafe { core::hint::unreachable_unchecked() }
}
In both cases we are using the following Cargo configuration:
[profile.release]
lto="fat"
opt-level="z"
panic="abort"
We can compile the std version with just cargo build
--release, but for the no-std one we will have to use nightly:
cargo +nightly build --release -Zbuild-std=std,panic_abort
Alright, let's measure it:
CMD RSS PSS SZ VSZ
./sleep-std-glibc 2116 318 806 3224
./sleep-no-std-glibc 1520 123 652 2608
./sleep-std-musl 264 264 140 560
./sleep-no-std-musl 28 28 47 188
So musl without std is almost as efficient as the static C implementation, which is almost as efficient as the raw assembly one. That's pretty good! Regrettably, awww's main branch is not currently fully no-std because I do not want to demand my users have the nightly toolchain to compile it. But it does have a no-libc-daemon branch, where the awww-daemon is implemented both without std and without depending on libc (maybe I should make a no-std branch where we still depend on libc for the BSD enjoyers out there, assuming they are using awww).
Not using libc bypasses the glibc vs musl and static vs dynamic linking altogether, since there will be no libraries to link to. It will also let us talk a bit about some very interesting libraries. Keep in mind I am assuming you are working in a fully no-std environment, since std uses libc under the hood. Also make sure to check every dependency to ensure they do not use libc themselves. Finally, this will only works on Linux because other Unixes (i.e. BSD) usually expose their syscall API as part of libc, and making syscalls in assembly is considered unstable.
3.1. The origin crate
Origin is a library to do program and thread startup and shutdown in pure Rust (in Linux). These routines can be quite tricky to implement, and Origin is even capable of offering us a proper _start symbol, setting up our environment so that our main function gets to look like this:
#[unsafe(no_mangle)]
#[cfg(not(test))]
pub extern "C" fn origin_main(
argc: usize,
argv: *mut *mut u8,
envp: *mut *mut u8
) -> i32 {
unsafe {
// we need to call this so that other calls in
// rustix::param work correctly
rustix::param::init(envp);
}
// ...
}
If you want to keep using the getenv implementation I've put above, you would also have to define a static variable environ (because this was previously offered to us by libc) and then set it to envp before doing anything else.
rustix's runtime module could spawn processes, but not threads. Origin can do both. Origin also takes care of the special treatment signal-handling needs to have (something you cannot correctly achieve with just rustix, because it does not implement the sigreturn syscall). If you are only targeting Linux, origin + rustix together can cover most of libc's use cases, baring some exceptional niche operations.
What's left is allocating memory and dealing with C library dependencies.
3.2. talc: allocate without libc
talc is an allocator that lets us decide how to handle the out-of-memory case, allowing us to offer it more blocks of memory when that happens. This is perfect because it lets us use rustix to mmap more memory when we need it. Other allocator libraries, like rlsf, ask for more memory from the OS directly through libc, so we can't use them. You can have a look at the awww-daemon's code to see how we implemented the OomHandler for talc using rustix here.
3.3. Manually compile C dependencies as freestanding
Now, it is possible to depend on C libraries, even in a no-libc environment! You just have to engage in a satanic ritual compile those libraries for a freestanding target. Not all libraries will allow for that, of course, but lz4, awww's only C dependency, does.
4. Limit allocations
Whew, let's get back to some more normal stuff, shall we?
Allocating memory increases memory usage. Obviously. But it does so more than one would naively expect. Memory allocators must use internal data structures to keep track of the size of each pointer and how much empty space is still available. Many of them will associate specific metadata to every allocated pointer. This means every allocation is using not just the allocated size itself, but also the metadata's size, and any fragmentation they may be causing in the heap. In contrast, the stack has neither metadata nor fragmentation associated with it (barring padding and alignment), and so using it will in general be more memory efficient.
There may be many places where one would think one needs a dynamic allocation, but that is not really the case. One classic example is when a certain OS interface has a limit on how big a string can be. We can just use an array directly on the stack for that. I will talk about two other interesting methods below.
4.1. smallvec
smallvec is a pretty popular crate that can store a certain number of items on the stack before "spilling" them over to the heap. Make sure you active its union feature, so that it occupies the same space as a normal Vec. A Vec is composed of 3 pointer-sized integers: the pointer itself, the length and the capacity. smallvec will use the capacity to know whether it is currently storing its data on the stack or the heap. So the goal is to use smallvec whenever the type you will store is ≤ two pointers in size, getting as close to it as possible.
For example, for a 64bit machine, you should use SmallVec::<[u32;4]> (uses all 16 bytes) and SmallVec::<[StructWithSize12;1]> (uses just 12 bytes, but we can't really do any better than this without increasing the SmallVec's size). Remember, SmallVec is using a union where one of its variants are two 64bit integers, this means it will always, at a minimum, use 16 bytes.
This gives us maximum efficiency when it comes to stack/heap utilization. Of course, if you know most vectors will be pretty big, this does not make any sense, as you'd be increasing code size for no benefit.
4.2. German Strings
German Strings can be thought of as a kind of specialized, immutable SmallVec. Because it is immutable we can drop the capacity integer. Also, we make the observation that almost no String will ever have a length greater than 4 GB, and so we can use only the first 4 bytes for the length. Then, we can use the other 12 bytes to store a string directly in the stack, if its len is ≤ 12.
If you need to store many small strings, using the German String representation can be a huge win, in both space and performance. That said, this is the only optimization I still haven't implemented in awww at the time of writing, because we can do even better: we know that strings sent through the wayland protocol can be at most bytes large, meaning we can store the length in just 2 bytes, and store up to 14 bytes in the stack, instead of 12! (4096 is the maximum message size. It would still have 8 bytes for the header and 4 for the string length, which gives us 4084)
If you need just a standard German String implementation, you can try out the strumbra crate.
5. Get rid of generics (as much as it is reasonable)
This is something many people know, but getting rid of generics can make your code shorter, because generics monomorphize when generating code, meaning the compiler generates a different version of the same function for every different type the function is called for. In contrast, if you use dynamic dispatch through dyn, the code generation will use a virtual table instead, and there will only be one function implementation for all types.
Wait, didn't I say multiple times we care about runtime memory cost, not binary size? This is something that will reduce the later, but shouldn't affect former, no? Well, kind of. If you measure awww-daemon's heap memory usage, you will find that when it's displaying just static images it uses around 2Kb of data (and around an extra 512b for every extra monitor you may have). That's less than a single memory page in most configurations! This means what's using memory in our application is actually the stack (in large part because we tried very aggressively reducing the number of allocations and reducing the size of our structs).
So now, if we want to further improve memory usage, we need to start looking at ways of making both the stack usage more efficient, and the code itself shorter, as the code needs to be loaded in memory by the OS in order to be executed. And yes, when we are in the realm of a few hundred kilobytes, it does make a measurable difference.
Having said that, don't be too gung-ho about this one. Be reasonable and make sure to measure things to see if it's actually changing anything.
6. Reduce struct sizes
I have a bit of an obssession with making my structs as space efficient as possible. This gets to the point where I can spent hours thinking just about how to organize my data differently instead of, you know, implementing actual useful features. You don't have to be as crazy as me, but you should always be aware of your structs so that they don't end up silently occupying far more space than they have to. This means keeping in mind padding and alignment, which are somewhat advanced topics (though we talked about far more advanced stuff here already) that I won't get into much detail here.
Rust has a nice bitflags crate that can help you packing up booleans, if it would help you.
6.1. Manual Rc<RefCell<T>> implementation
For a while, a Wallpaper in awww was stored as a Rc<RefCell<Wallpaper>>. These things were then put inside a Vec. Now, a standard Rust Rc is a wrapper that will store a pointer to a RcInner object, containing three fields: two usizes for strong and weak reference counting, and the type you want to store. A standard Rust RefCell has itself your value wrapped in a UnsafeCell and a usize counting the number of borrows. This gives us a grand total of 24 extra bytes per object.
Here's the thing though:
- I do not care about the weak counter;
- I know for a fact the strong counter can only go up to at most 3; and
- All of my borrows are always unique.
This means I can store all the information I need with just a u8 counter for the Rc, and just a boolean flag for the RefCell. Furthermore, I can store both these values inline with the Wallpaper for no cost, because of alignment and padding. So, by making my own manual implementation, we can use 24 less bytes per object!
Because awww-daemon will probably never deal with more than 8 wallpapers at once (who the hell has more than 8 monitors?), this turns out to be a rather niche and possibly not that important optimization compared to some of the other stuff in here, but it is one that brought me great peace of mind, since I can rest easy knowing my structs are not wasting all that extra space (I did say I was obsessed). Anyway, if you have many objects wrapped around these structures, maybe study a bit whether manually reimplementing them won't give you a huge win, depending on your use-case.
6.2. Always be aware of your enum variant sizes (Box them if needed!)
Clippy has a warning for this, that by default will warn you if a variant of your enum is 200 bytes larger than the (I believe) the second largest one. This is a problem because the enum will occupy at least as many bytes as its largest variant.
The easiest fix is wrapping your variants in Box. This will incur an extra allocation, but it will be worth it if the smaller variants are more likely to be stored than the large one. You can also try carefully thinking about your data to figure out whether there is a different, more efficient way of representing exactly what you want.
This advice is much simpler than most of the stuff in this page, but it is one that caught me quite off-guard. In fact, I only realized one my variants had ballooned in size because of the aforementioned Clippy warning. Sometimes it's the simple stuff that gets you.
7. Manual log implementation
Alright, this one's really annoying. The great log crate, which everyone uses for their logging needs. Its macros accept 4 formats (exemplified here with the debug macro):
debug!(logger: my_logger, target: "my_target", "fmt str", args)debug!(logger: my_logger, "fmt str", args)debug!(target: "my_target", "fmt str", args)debug!("fmt str", args)
These were taken straight from its source code. Here's the kicker: to support the first 3 formats, log must include some extra code and processing. But, if you only ever use the final format, that's just extra overhead for no reason.
If you only care about the fourth format, implementing our own log with the exact same macro API is actually pretty easy, but the reason this is annoying is that we lose logging in all our dependencies, since they would be using the standard log facade. Luckily, awww doesn't depend on anything for which log would be useful, so we are ok, but this won't really be an option for some other projects.
The main thing about this is that it reduces binary sizes if you aren't compiling while optimizing for size. As mentioned, we can't optimize for size in our case because it would not vectorize the image transition animations, making them grind to a halt. Since we are optimizing for performance, Rust will inline the extra unnecessary log basically everywhere it is called (also, the macro implementation themselves expand to more code than what's strictly necessary). So, if you are doing a lot of logging, this can indeed make a fair bit of difference.
As a bonus, I implemented a Fatal log filter level to use in my panic handler, which looks quite nice!
8. Manual CStr parsing
In a no-std environment, you will inevitably be dealing with lot of CStrs. The environment variables, argv and system Paths (if you have been following my advice), are all CStrs. But Rust does not implement the parse method for CStr, only for str. So, if you need to, say, parse an integer from a CStr, you have two options: perform a fallible conversion to str and then do a fallible attempt at parsing, or implement the parsing manually yourself. If you somehow got this far into this post, you can probably guess which option I went with.
There is in fact the atoi crate for parsing integers, and, if you need to parse floats, there is fast_float. I didn't use them because my use-case was far too simple, so I just wrote it manually.
Final Words
And that last sentence is really the main thing I would like people to understand. If you want to maximize performance or, in our case, space efficiency, you must not be afraid of looking into other libraries, seeing how did they something, and thinking about how you can adapt it to your use-case as efficiently as possible. Yes, you have to make sure you only do that for code you can actually understand and reliably maintain (do NOT roll your own TLS, you deranged idiot!). But a lot of times I've found I was depending on a crate for just one or two functions. We can just put them in our code directly, often making them much better for our particular program. That's what I did with the keyframe crate. Eliminating some of its unneeded (manual) dynamic dispatched reduced the size of some of my structs, since we needn't store an extra function pointer.
Many of these techniques could be applied to either simple one-off binaries, or simple long-running daemons. For example, I believe it might be possible to enhance the coreutils rewrite with some of this stuff. Smaller binaries tend to also execute faster in general, so it would be an all-around win.
I've also considered trying out a Rust cron implementation using some of this. I believe cron is a good candidate for such an implementation because it has relatively simple and well-stablished behavior. As a daemon, it will be running permanently, and thus minimizing its memory runtime costs could lead to huge wins over a long period.